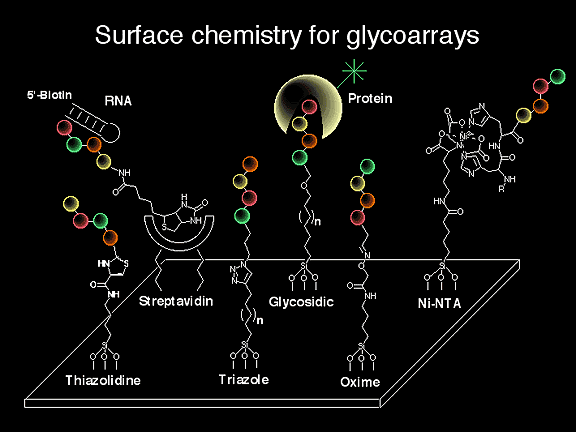| |
Antivirals, Anti-Cancers, and Antibiotics in One Pot
"Blueberries
as big as the end of your thumb,
Panning parts of the chemical universe for compounds that are active against particular biological targets has been an established route to drug discovery since the early days of modern biology. In 1909, for instance, Paul Ehrlich tested hundreds of chemicals and eventually found one that could be used to treat syphilis. And Alexander Fleming was searching for an effective antiseptic when, in 1928, he happened upon a mysterious bactericidal substance (penicillin) produced by mold growing in his petri dish. There is no shortage of human diseases and frailties and there is no question that these conditions can be treated or prevented through molecules that, like penicillin, disrupt some part of the disease process. Molecules on the outside of cancer cells, for instance, facilitate disease progression and allow the cells to grow uncontrollably and invade other tissues. Viral pathogens like HIV, hepatitis virus, and influenza use surface molecules to recognize specific cells and invade the human body. They use other molecules to replicate. The same is true for bacterial invaders. And if chemicals can be found to inhibit any of these recognition molecules and enzymes, then they might make good drug candidates. Now that the genome has been solved, and as it is annotated, more targets are being identified every year. For every new target discovered, there are 100 hopeful Flemings looking for the next potential penicillin in the proverbial petri dish. The lion's share of such drug research has long involved the interactions of small molecules with proteins or nucleic acids. Carbohydrate recognition, which surely has important biological activity given the volume of carbohydrates in the body, has lagged behind the fields of protein and nucleic acid recognition. Even so, TSRI and Skaggs Institute for Chemical Biology investigator Chi-Huey Wong, who holds the Ernest W. Hahn Professor and Chair in Chemistry, suspects that times are changing. As a chemist specializing in molecular manipulation, Wong's major interest has long been in carbohydrate recognition. He, for one, is interested in searching within that part of the chemical universe hard to delve into up to now—the part inhabited by carbohydrate structures—and he is not alone. He predicts that in the near future, researchers will pay much more attention to this area. Carbohydrate RecognitionCarbohydrate structures are very much part of the language of life. They are like the accents on spoken words—they change the meaning without changing the spelling. Some even call carbohydrates the third alphabet, behind DNA and proteins. Though they are not charged with storing genetic information like DNA or acting as enzymatic workhorses like proteins, carbohydrates nevertheless do carry information and are responsible for important biological functions, playing a central role in many types of intercellular communication events, particularly in the immune system. All cells, foreign or human, are covered with them. Some viruses, like HIV and influenza, use sugars on the outside of human cells to gain entry, and immune system cells use carbohydrate-binding proteins to detect subtle differences in sugar structures on the surface of cells to recognize foreign pathogens. Sometimes the carbohydrate-binding proteins and their sugar ligands are expressed on the same cell, and the sugar is part of the regulation machinery of the cell. Indeed, the major histocompatability complex, which is responsible for the recognition, is composed almost entirely of glycosylated proteins. Wong attributes the fact that carbohydrate recognition has been much less studied than other areas of molecular recognition but not due to any lack of interest on the part of biologists. Part of the problem is the large number of polysaccharides that exist. The diversity of sugars is incredible. The human body contains only nine monosaccharide building blocks from which it assembles carbohydrate structures, but, unlike the components of nucleic acid, they can link together in multiple, non-linear ways because each building block has about four functional groups for linkage. They can even form branched chains. Hence, the number of possible polysaccharides is enormous—the number of possible four-sacchraride chains you can form from the nine monosaccharides is greater than 15 million. An even greater barrier to studying polysaccharide recognition, though, is that the structures are difficult to work with. "We simply do not have the tools to study [carbohydrate recognition]," says Wong. "We don't have PCR for amplifying sugars and we don't have a machine for synthesizing sugars." One-Pot SynthesisThe lack of commercially available or easy-to-make carbohydrate structures has been called the single biggest bottleneck in the field. And nobody is more aware of this problem than Wong, who has worked arduously in recent years to design methodologies for supplying carbohydrate structures. The basic technique that Wong uses is one he designed a few years ago, called programmable one-pot synthesis. This technique basically involves placing a large number of specific chemical building blocks into a reaction vessel and then making sequential chemical reactions in the soup. The final products depend entirely on the particular reaction scheme followed. The one-pot technique allows Wong to quickly assemble many types of carbohydrate structures—in just minutes or hours, depending on how complicated the chemistry is. Wong even developed software that he uses to streamline the process. "The computer will tell you which building blocks to use and you simply add them in sequence," he explains. Depending on the type of building blocks used and the size of the final structures, the pool of compounds made in this way can be quite large. For instance, placing 300 building blocks in a pot and randomly combining them into tetramers will yield over eight billion compounds. Once the oligosaccharides are made, these carbohydrate "libraries" can be used for any number of biological studies. One of Wong's main uses for the libraries is screening against various types of biological targets to look for interactions. Wong is also trying to perfect procedures for attaching the carbohydrates to a solid phase so that they can be easily presented for screening against some biological target. He has already perfected the chemistry needed to do so, and he can attach designed linkers to his carbohydrate molecules. The next step is to determine the best way to quickly and accurately deposit these molecules onto surfaces on a very small scale, so that a "carbohydrate chip" can be prepared. Wong is still working out the technology to do this, but in preliminary demonstrations he and his laboratory group have assembled and affixed arrays of carbohydrates onto microtiter plates by pipeting. "It is possible to assemble millions of molecules on a polystyrene surface or glass slide," he says. Knowing where the carbohydrate molecules are on the chip, one can profile a particular carbohydrate-based receptor–ligand interaction, looking for drug candidates, for instance. Targeting RNA Instead of ProteinsWong is already using the compounds he has created through his one-pot syntheses to pursue many different biological targets. One of the key molecules that Wong is looking at is RNA, and he is trying to come up with carbohydrate structures that specifically target various RNA sequences. RNA is a legitimate target. Many viruses use RNA as their genetic material, so one could attack this RNA. Moreover, RNA is ubiquitous in biology, so there is not a single pathogen or human disease state in which it is not an integral part. And one might consider that RNA's location in the cytoplasm of cells—out in the open, as it were—makes an even better target. Furthermore, many proteins are difficult or impossible to express and purify in the laboratory, making them simply unavailable for research. This is particularly true of glycoproteins, which undergo post-translational modifications that cannot be duplicated in expression systems. Other proteins are impossible to target specifically because their binding sites are too similar to the binding sites of many other proteins in the body. There are thousands of kinases that use the same mechanistic means to accomplish a multitude of biological ends. Giving a person a drug that interferes with the one would disrupt the function of the whole lot. "How do you come up with a selective inhibitor against just one?" asks Wong. And his answer, simply, is that you forget about targeting the protein and set your sights on the RNA from whence it comes. If you can bind to a particular sequence of the RNA and block its translation into protein, then you are effectively circumventing the need to block that protein. Wong turned his attention to RNA a few years ago when he asked whether it would be possible to come up with molecules that target RNA with high affinity. Such an RNA-binding motif is already, conveniently, known in a certain class of antibiotics currently on the drug market. The aminoglycosides, which include streptomycin and gentamicin, bind to the 30S subunit of ribosomal RNA of bacteria like Staphylococci and Mycobacteria. All aminoglycosides contain one particular "b-hydroxyamine" motif that is critical for the interaction with the RNA. Once Wong had realized that, he set about designing a library of carbohydrate compounds—"aminoglycoside mimics" he calls them—based on this b-hydroxyamine motif that binds RNA. With the library, he is targeting a number of different types of RNA, including oncogenic RNA (in collaboration with TSRI Professor Peter Vogt), HIV and hepatitis C viral RNA, and bacterial RNA. For each he identifies particular, unique RNA sequences that he can target and tests these sequences against his library. One new antibiotic that Wong developed based on the aminoglycosides is lethal to over 200 kinds of gram negative (lipopolysaccharide-covered) and gram positive (peptidoglycan-covered) bacteria. "It kills almost every bacterial species we test," he says. The preclinical studies on this antibiotic are now being pursued by Optimer Pharmaceuticals, Inc., an outside company Wong co-founded. Wong has also identified a 5' untranslated region of the hepatitis C viral genome that is essential for the binding of the ribosome and the assembly of the virus. This region is highly conserved and absolutely essential for the viral lifecycle. "We want to come up with small molecules that target this sequence," says Wong. Similarly, he has identified a unique, conserved, essential sequence in HIV RNA that he uses as another target for panning.
Using the programmable one-pot synthesis technology and novel surface chemistry for microfabrication, the Wong group has created massive glyco-arrays for discovery of small molecules recognizing a target RNA or protein specifically.
One Laboratory, Many TargetsWong is also panning for inhibitors of enzymes involved in cancer metastasis. When cells move from one tissue to another, they have to detach from the surface of the old tissue and make new attachments on the surface of the new tissue. Many of these interactions involve carbohydrate recognition, and Wong is designing small molecules to mimic these carbohydrates. A portion of Wong's laboratory is also working on vaccine design by identifying antigens that are displayed on the surface of cancer cells, bacteria, and viruses. Screening his libraries can reveal which particular parts of the pathogenic surface are visible to the immune system, and therefore which would make good vaccine candidates. One final target that Wong has in his sights is that of HIV protease, an enzyme that the virus uses to process viral proteins to make infectious virus particles. For the last several years, the greatest weapons doctors have had for treating HIV infections have been antiretroviral drugs that tightly bind specific viral enzymes necessary for replication and infection—the protease and reverse transcriptase inhibitors, for instance. Highly active antiretroviral therapy (HAART), which combines both classes of drugs together into one treatment, has proven particularly effective, as demonstrated by the decline in AIDS mortality in the United States in the last few years. However, the last few years have also witnessed the rise of drug-resistant strains of HIV in patients on HAART. Because HIV's genome is short and composed of only the essentials it needs for replication and infectivity, it lacks the luxury of a proofreading mechanism—which mammals, for instance, use to ensure fidelity in cell replication and division. The fidelity of HIV is so low that it makes an average of one mistake every time it replicates. And because it replicates so much in an infected host, mutant variants quickly arise. These variants are often resistant to HAART drugs but are still able to replicate. The drugs lose and the infection wins. As a result, more and more inhibitors have been designed in recent years, alongside a plethora of combinations and dosage schedules that aim to maximize the effectiveness of the drug. "HIV drug resistance is a major problem," says Wong. "If you design a perfect drug, it may not be a good one from a therapeutic point of view." So Wong has taken a different route. He has designed an inhibitor that is intentionally imperfect, with broad activity rather than specific. This inhibitor, which targets the viral protease that HIV uses to assemble infectious virions, is ten-fold less active than some of the weakest HIV protease inhibitors on the market, but it is active against almost all variants of the viral enzyme. Mutations in the protease are less likely to knock out its effectiveness. "It is based on our understanding of how the protease evolves and how the structure changes to escape." In preliminary studies, the inhibitor is effective against a broad range of similar proteases from a range of HIV and related viruses in cell culture assays, and further studies are being pursued. Interestingly, five years ago, one might not have guessed that a less potent inhibitor could be a good thing, or that sometimes the road less traveled would be a better route to drug discovery.
|
| |